CodeHealth as a Prerequisite and Compass for Coding Agents
CodeScene research direction maintained by Dr. Markus Borg
Thesis: High-quality code has never been more important than in the AI era.
-
Healthy code is more AI-friendly: it is easier for coding agents to analyze, modify, and extend without introducing unintended side effects.
-
Human readability remains vital as the volume of AI-generated code grows. The future will be hybrid, and humans will continue to read, review, and reason about code when it matters most.
Code quality is a prerequisite for successful agent deployment
We studied refactoring success as a proxy for how effectively AI systems can work with code of varying quality [2]. Our experiments use the public training set of competitive programming solutions released with DeepMind’s AlphaCode. Across these experiments, LLMs consistently perform better when operating on healthier code.
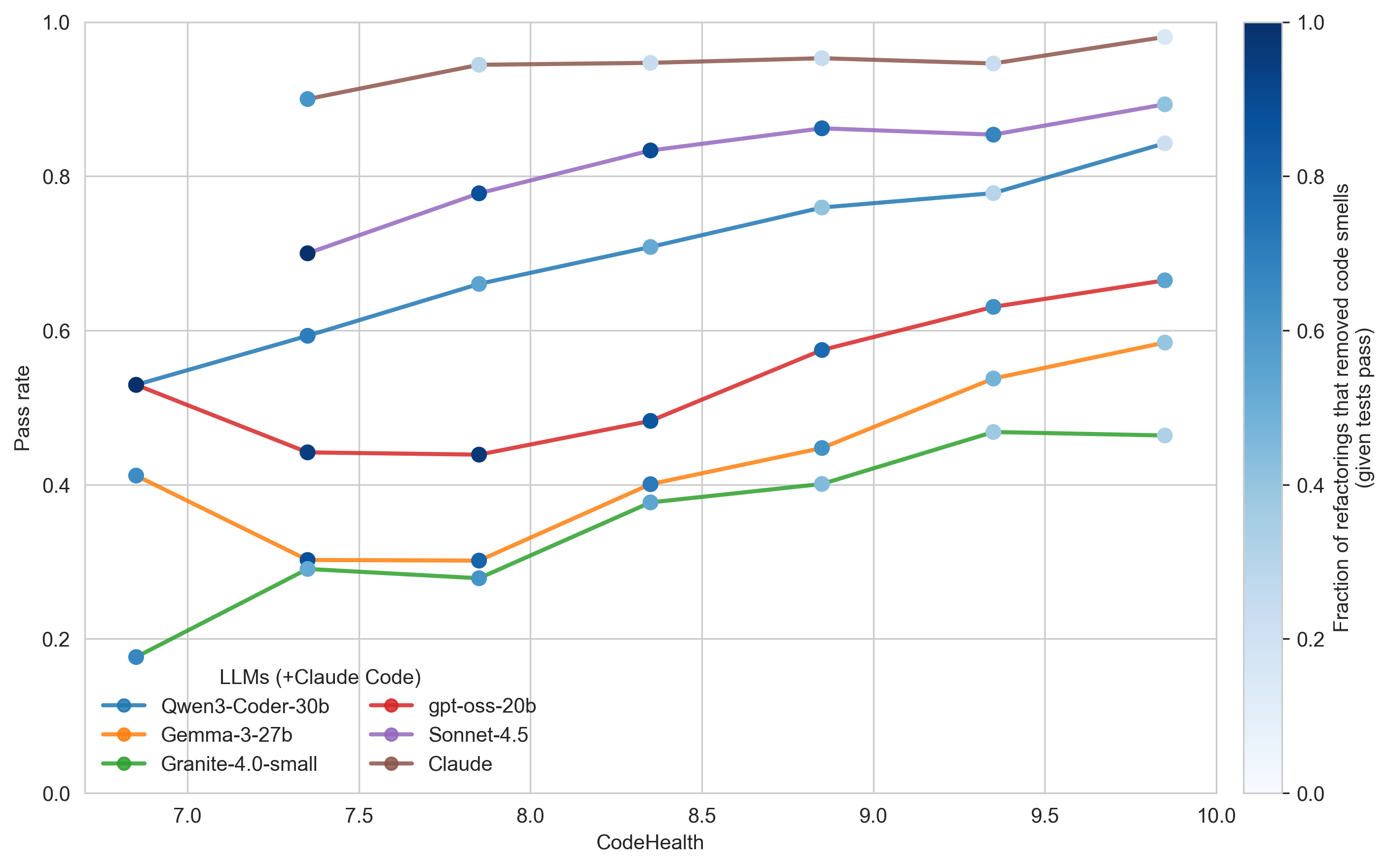
Figure 1 below shows test pass rates as a function of CodeHealth when LLMs are prompted to improve maintainability in Python files. For reference, Claude Code pinned to Sonnet 4.5 is shown alongside other models (brown curve). The color of each data point indicates the fraction of refactorings that removed at least one code smell, conditional on passing tests.
Takeaways
- Higher CodeHealth decreases refactoring risk across all evaluated models.
- The trend is consistent across model classes, from medium-sized open models to state-of-the-art Sonnet 4.5.
- As CodeHealth increases, LLMs identify fewer code smells to remove, reflecting a shift toward more cosmetic changes.
- Claude exhibits the most conservative behavior: the lighter blue markers reveal that many test-passing refactorings involve limited structural change (reported in related work [5])
Coding agents need CodeHealth guidance
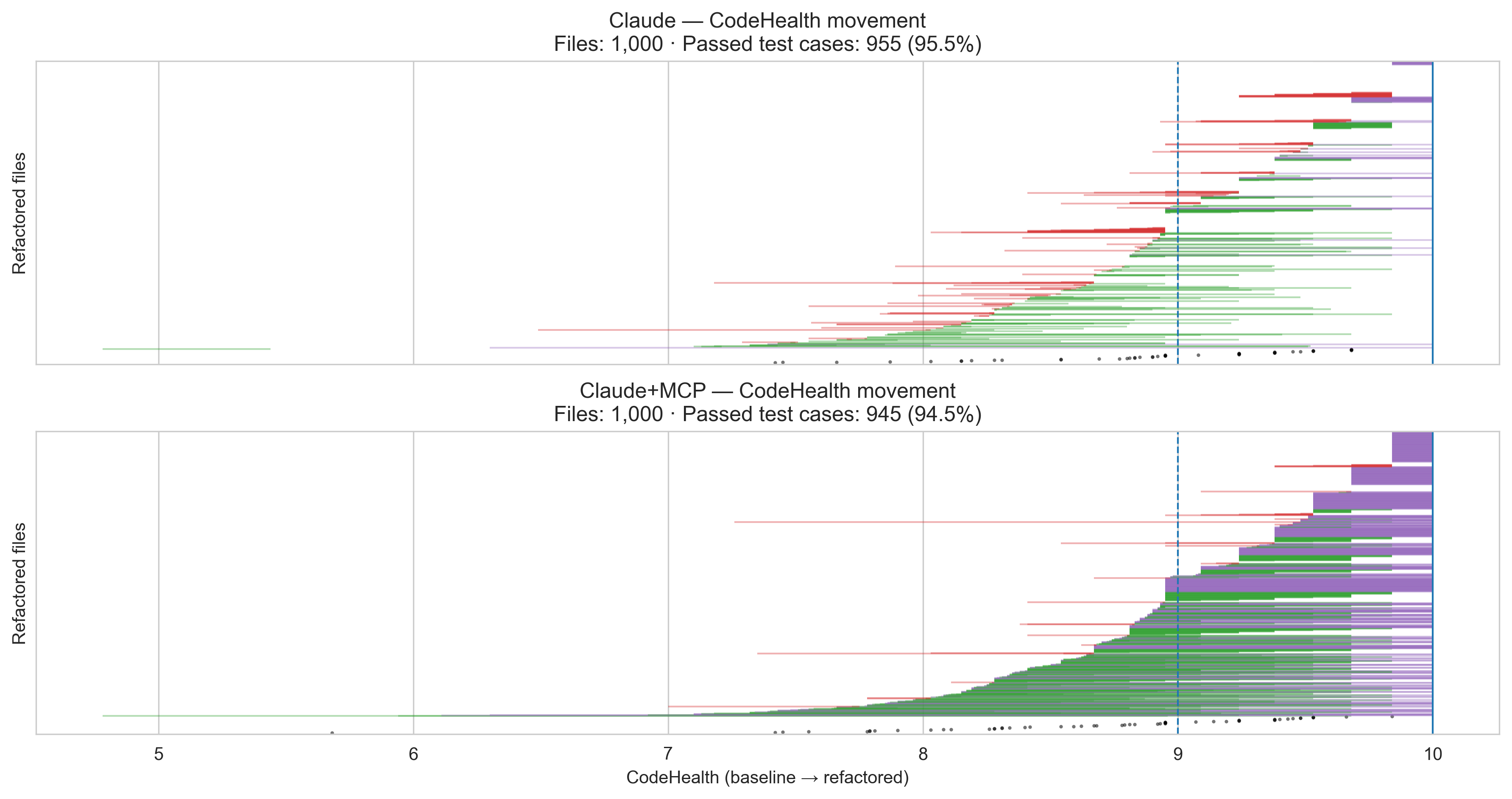
We studied the effect of giving Claude Code access to CodeHealth through our MCP server. As shown in Figure 2, explicit CodeHealth guidance fundamentally changes how capable the agent becomes.
The upper plot shows file-level results for Claude corresponding to the brown curve in Figure 1. The lower plot shows the same setup with CodeHealth provided as an explicit compass for the agent.
Each horizontal line represents the CodeHealth journey of a single file, sorted vertically by their original CodeHealth:
- Green lines indicate files whose CodeHealth improved; line length reflects the magnitude of improvement.
- Purple lines indicate files that reached a perfect CodeHealth score of 10.
- Red lines indicate files whose CodeHealth decreased.
- White gaps correspond to files whose CodeHealth remained unchanged.
- Black points mark refactorings that did not pass the test suite.
Takeaways
- CodeHealth provides a clear optimization target for iterative agentic refactoring.
- Claude maintains a high test pass rate (≈95%) even while making structural improvements.
- In every second file (52%), all code smells are removed, compared to only 5.7% without CodeHealth guidance.
- Most files improve substantially: more than 90% reach a human- and AI-friendly state, compared to 24.1% without CodeHealth guidance.
The value of using CodeHealth as a compass also generalizes to C++ and Java, supported by large-scale experiments with a self-hosted coding agent and medium-sized LLMs. Learn more.
What Is CodeHealth™ — and Why It Matters to the Business
CodeHealth is the only code-level maintainability metric with demonstrated, peer-reviewed business impact. It is measured on a scale from 1 to 10 and is calibrated to align with how engineers perceive code maintainability. A score of 10 represents code that is free from code smells and easy for humans to read, understand, and evolve.
Across multiple peer-reviewed studies, we show that higher CodeHealth is associated with outcomes that matter for software-intensive organizations:
- Healthy code is associated with, on average, 15× fewer defects, 2× faster feature implementation, and 10× lower uncertainty in task completion [6]
- Newcomers struggle with unhealthy code, requiring up to 45% more time for small changes and 93% more time for larger changes [4]
- CodeHealth provides a shared language for discussing the business impact of code quality with executive stakeholders [3]
- CodeHealth outperforms established alternatives, performing 6× better than SonarQube’s metric on a public benchmark and outperforming the traditional Maintainability Index [1]
In a hybrid future where code is co-developed by both humans and AI, CodeHealth provides guardrails for agents and preserves human program comprehension when oversight is needed.
References
- Borg, Ezzouhri, and Tornhill. Ghost Echoes Revealed: Benchmarking Maintainability Metrics and Machine Learning Predictions Against Human Assessments. In Proc. of the 40th Int’l. Conf. on Software Maintenance and Evolution (ICSME), 2024. arXiv
- Borg, Hagatulah, Tornhill, and Söderberg. Code for Machines, Not Just Humans: Quantifying AI-Friendliness with Code Health Metrics. In Proc. of the 3rd ACM Int’l. Conf. on AI Foundation Models and Software Engineering (FORGE), 2026. arXiv
- Borg, Pruvost, Mones, and Tornhill. Increasing, not Diminishing: Investigating the Returns of Highly Maintainable Code. In Proc. of the 7th Int’l. Conf. on Technical Debt, pp. 21–30, 2024. arXiv 🏆 Best Paper Award
- Borg, Tornhill, and Mones. U Owns the Code That Changes and How Marginal Owners Resolve Issues Slower in Low-Quality Source Code. In Proc. of the 27th Int’l. Conf. on Evaluation and Assessment in Software Engineering, pp. 368-377, 2023. arXiv
- Ottenhof, Penner, Hindle, and Lutellier. How do Agents Refactor: An Empirical Study. In Proc. of the 23rd Int’l. Conf. on Mining Software Repositories (MSR), 2026. arXiv
- Tornhill and Borg. Code Red: The Business Impact of Code Quality – A Quantitative Study of 39 Proprietary Production Codebases. In Proc. of the 5th Int’l. Conf. on Technical Debt (TechDebt), pp. 11–20, 2022. arXiv


