Multi-language Evidence: Guiding Coding Agents Beyond Python
This page provides supporting evidence that the value of using CodeHealth as a compass for coding agents generalizes beyond Python.
For this series of experiments, we deployed a self-hosted instance of the open-source coding agent gptme on infrastructure equipped with NVIDIA A100 GPUs. On the same server, the agent used Qwen3-Coder-30b as the underlying LLM. This is the strongest medium-sized model we have worked with and, critically, it supports tool calling and integration with the CodeScene MCP server. For each file, the agent was allowed up to 50 refactoring iterations.
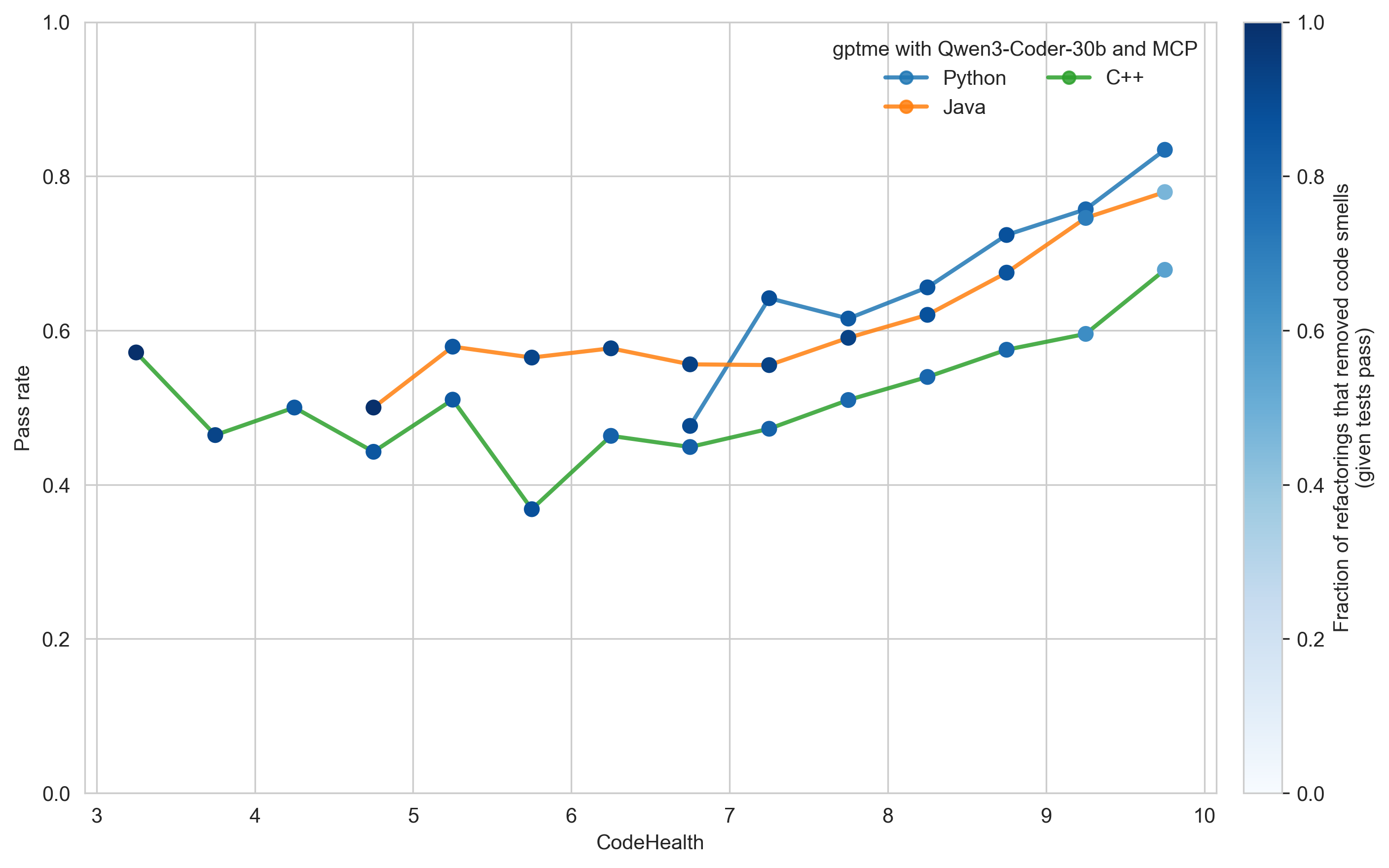
Test pass rate as a function of CodeHealth
Takeaways
- The relationship between CodeHealth and refactoring reliability generalizes across languages once CodeHealth exceeds approximately 7.
- Agentic refactoring is most effective for Python, slightly less so for Java, while C++ is more challenging.
- Explicit CodeHealth guidance helps keep even a less capable agent on track, as indicated by the predominantly dark-blue markers corresponding to meaningful code smell removal.
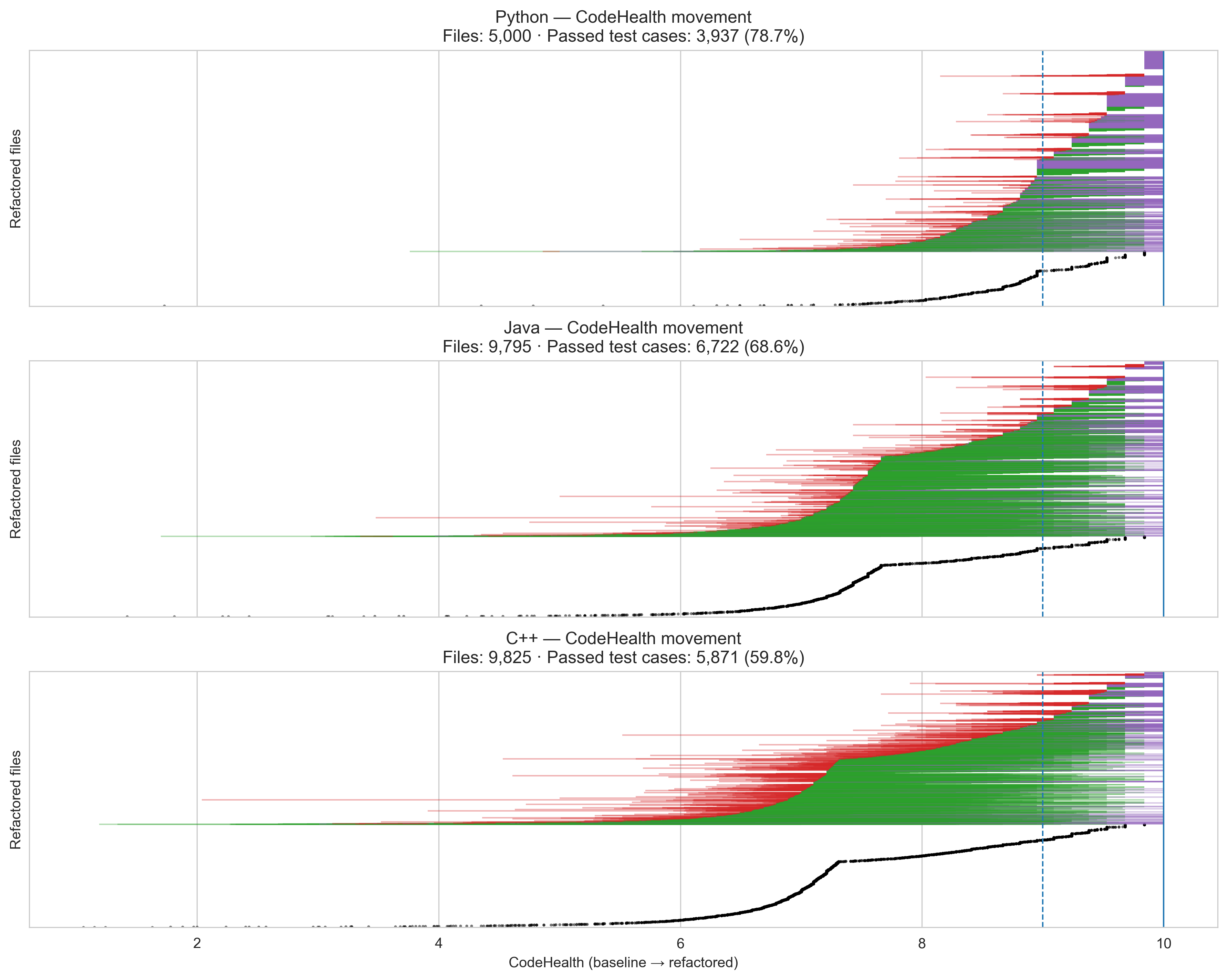
File-level refactoring results
Each horizontal line represents the CodeHealth journey of a single file, sorted vertically by their original CodeHealth:
- Green lines indicate files whose CodeHealth improved; line length reflects the magnitude of improvement.
- Purple lines indicate files that reached a perfect CodeHealth score of 10.
- Red lines indicate files whose CodeHealth decreased.
- White gaps correspond to files whose CodeHealth remained unchanged.
- Black points mark refactorings that did not pass the test suite.
Takeaways
- Python shows the strongest outcomes: gptme frequently removes all detected code smells, as indicated by purple lines.
- Java exhibits more conservative improvements: fewer files reach a perfect CodeHealth score, but decreases in CodeHealth (red) are typically smaller in magnitude.
- C++ presents the most mixed results: only 52% of refactored files pass the test suite, and CodeHealth changes span a wide range in both positive and negative directions.
This research was conducted at CodeScene and Lund University with support from Vinnova, Sweden’s Innovation Agency.


